Dear Richard,
Sorry, this query is getting longer and the fronts are diverging, however there are still some points that I don’t understand. These 2 stations are working fine now, they acted in a strange way during 3 days, but they recovered the expected behaviour, so I’m not sure about the electronic explanation…
Quoting your last answer :
- “what i now think is going on is that instead of the problem having anything to do with data being sent to the server, the problem instead lies with the data not being properly read off the serial port. it cannot be a coincidence that when the problem sending data to the server is solved happens to be the same moment when the data-producer program is restarted. so the problem with data flow stopping must be further upstream.”
I don’t understand this new explanation. In a precedent answer (#14, Feb, 25) I was told: the IP addresses for these two machines were banned from being able to communicate with the server at all, thus preventing the connection request from even getting in. Your query prompted these IP addresses to be “un-banned” to test if they were the same units you had reported, and to see if the network problem had resolved; it was true in both cases.
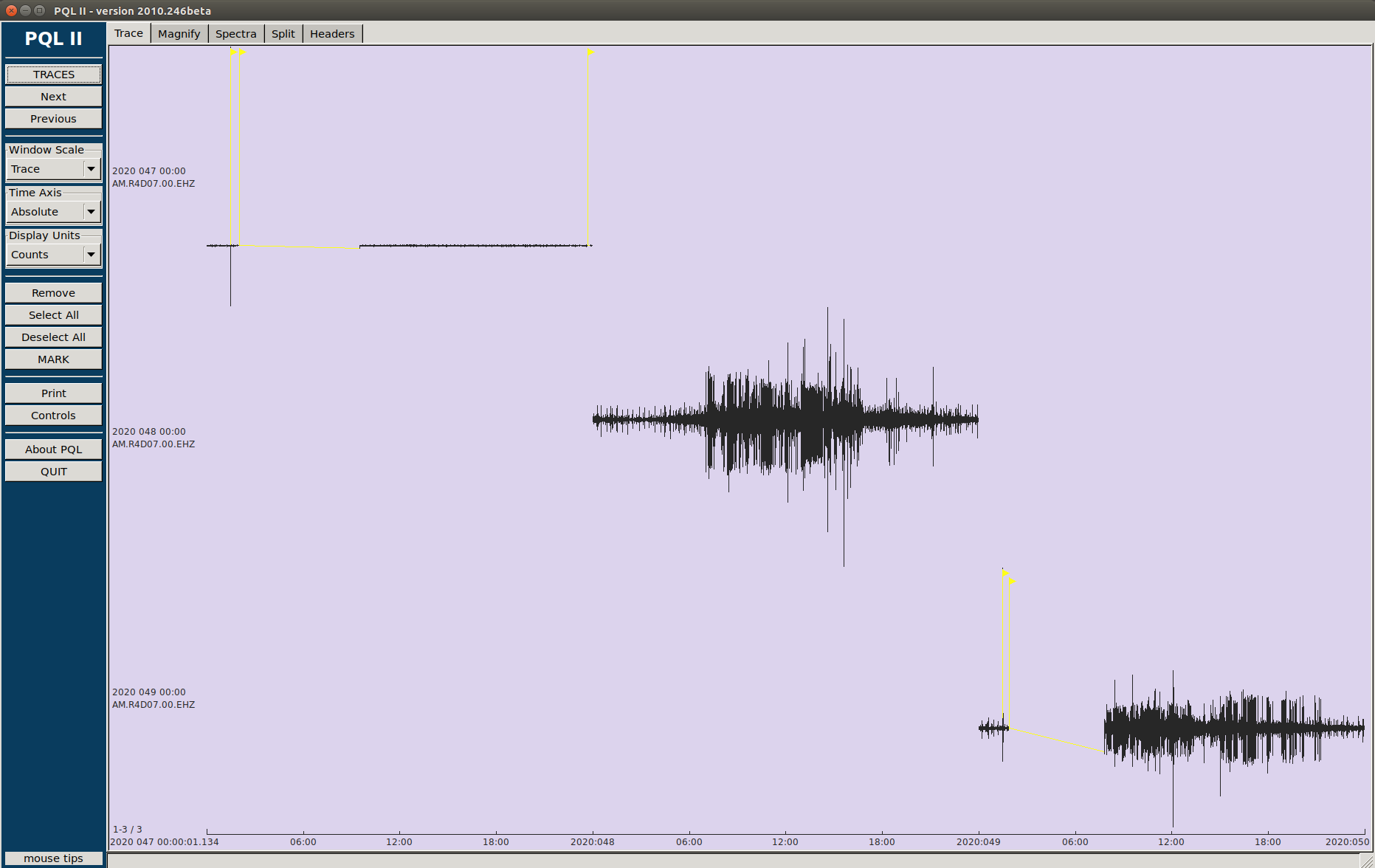
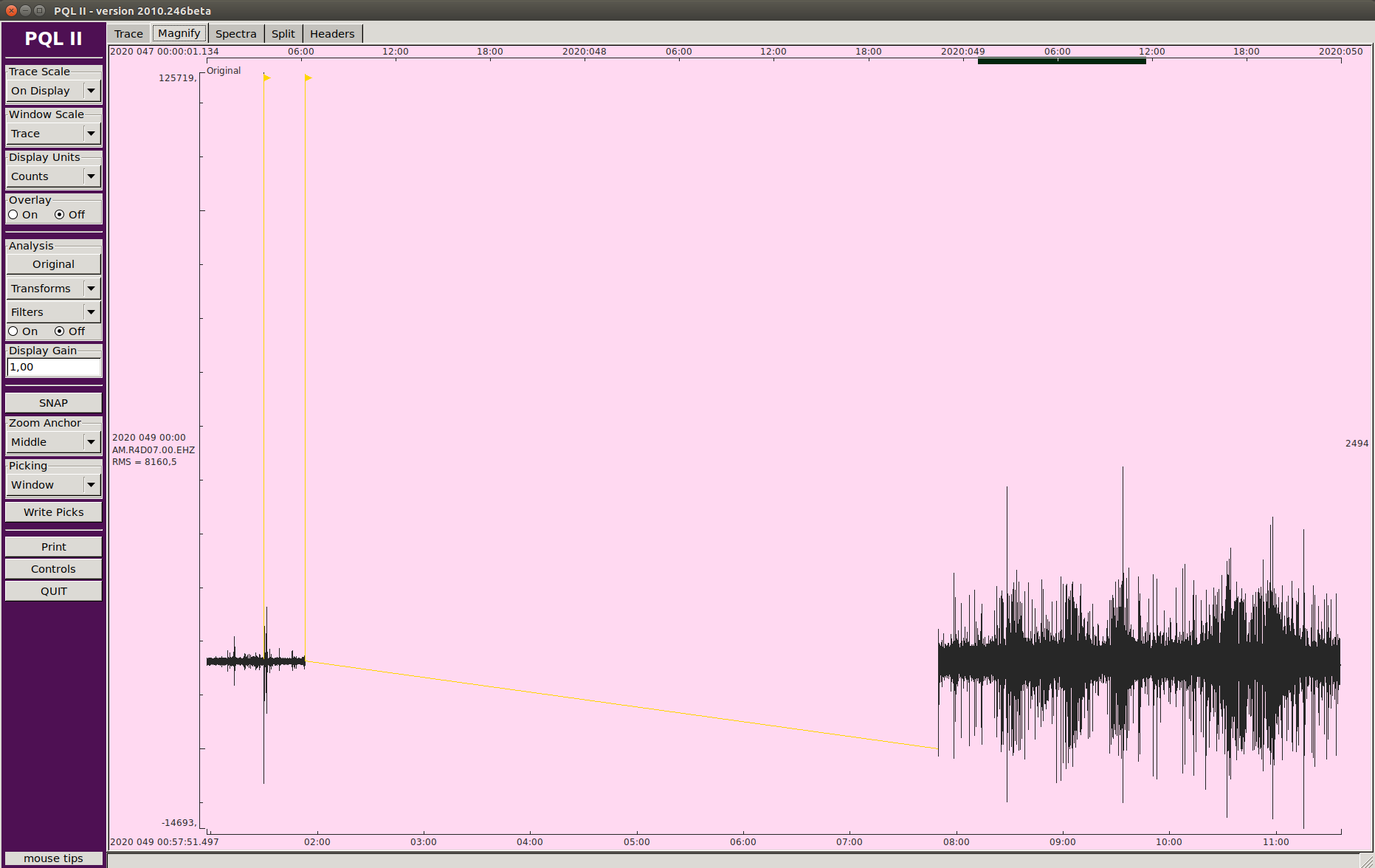
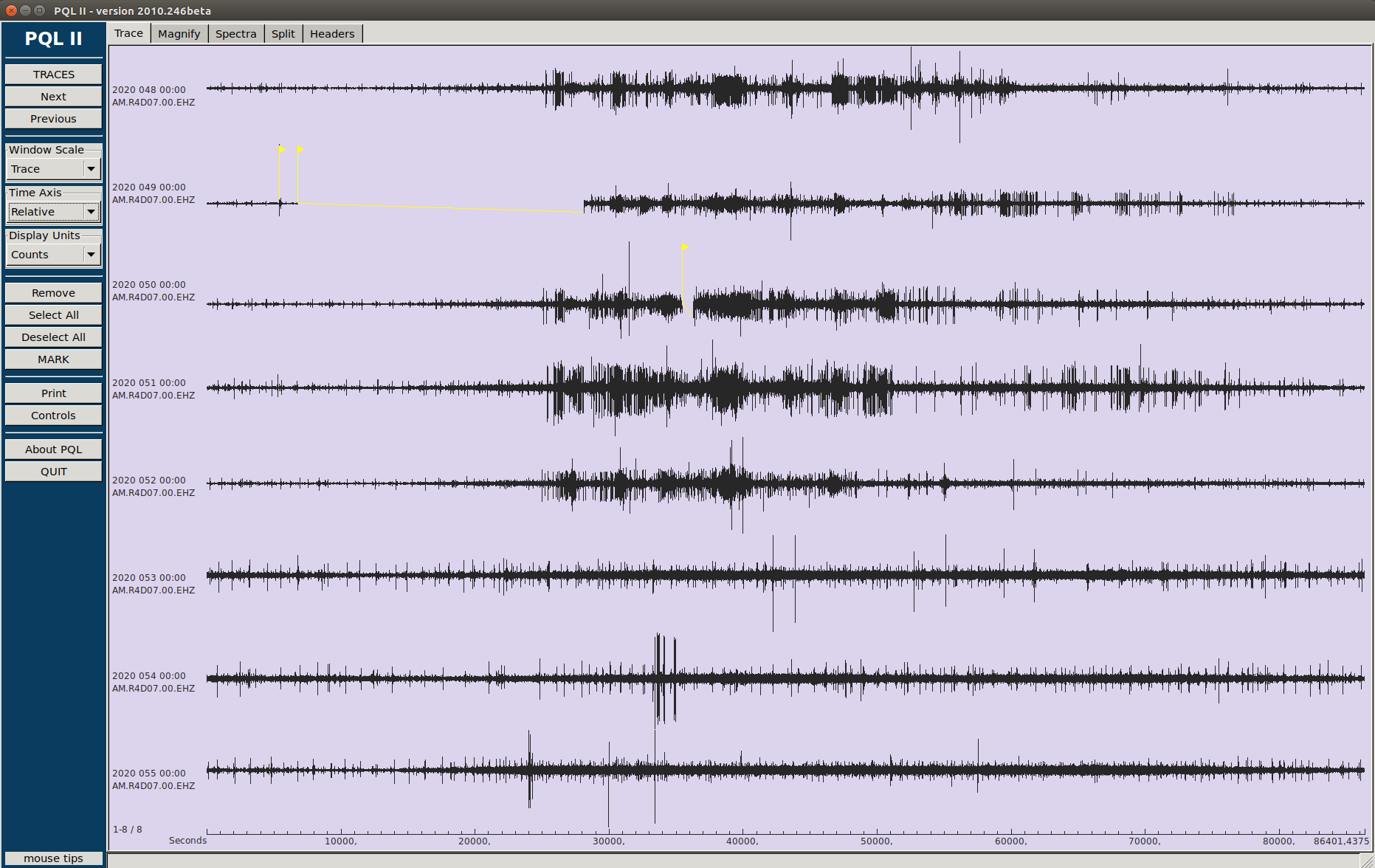
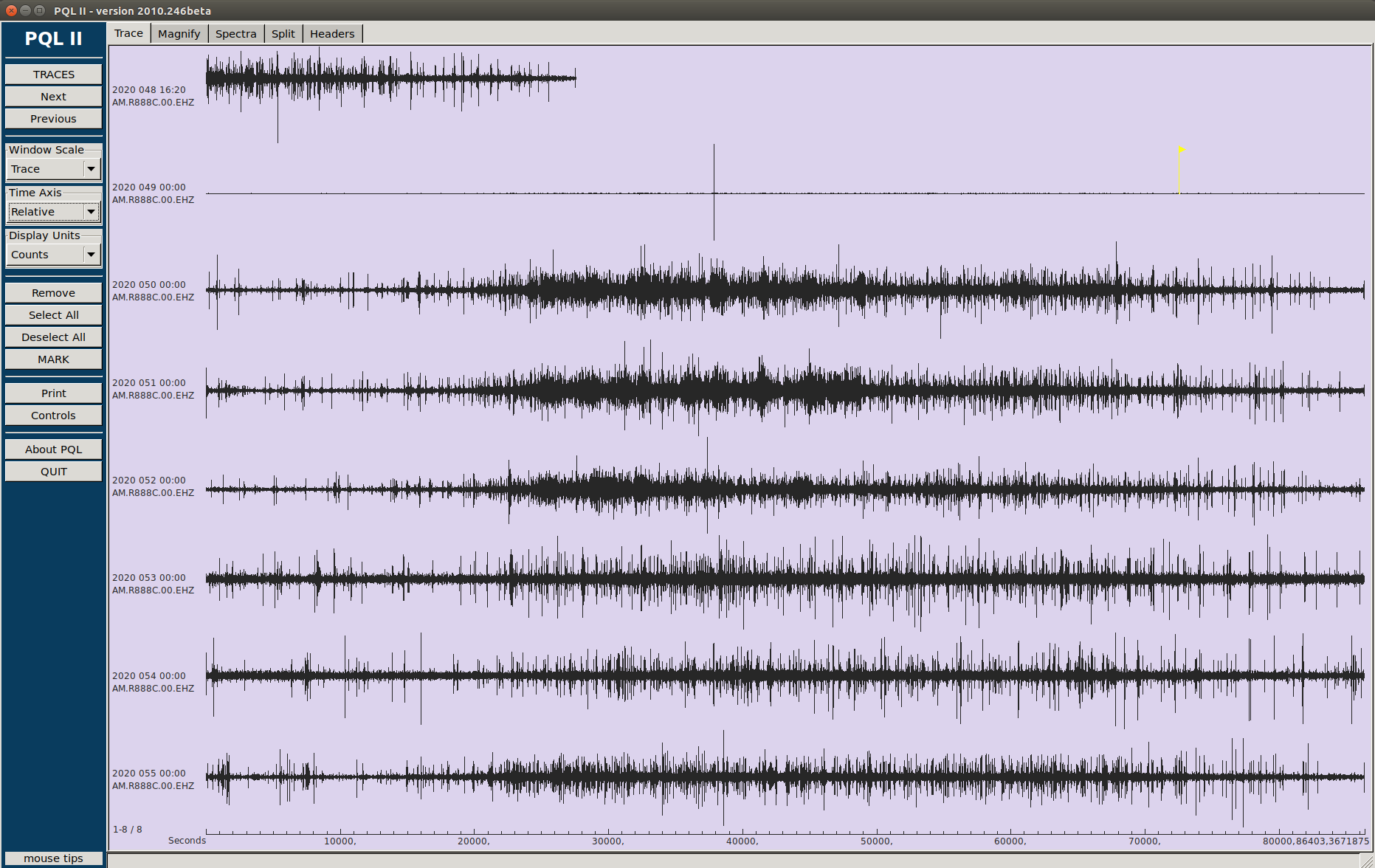
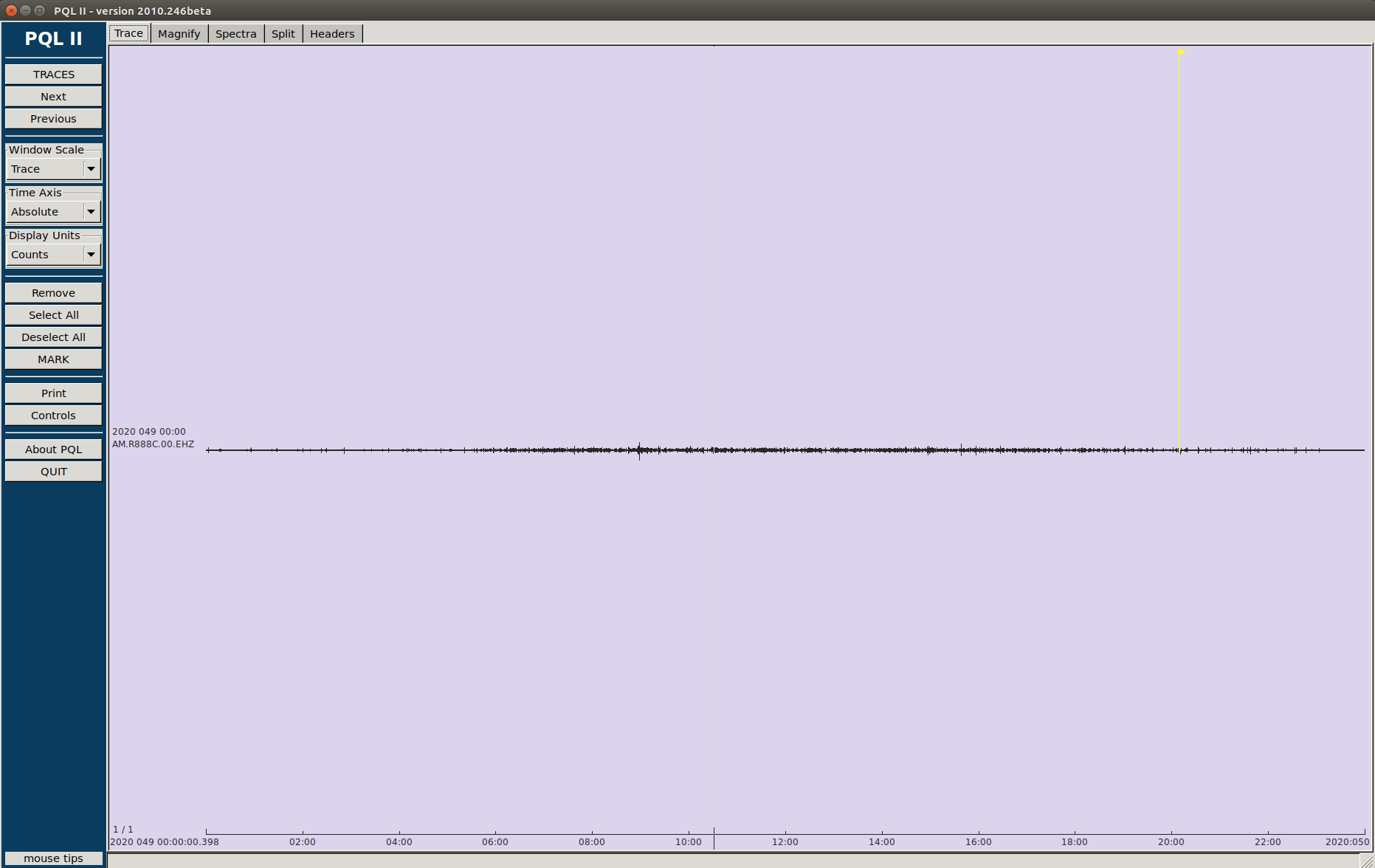
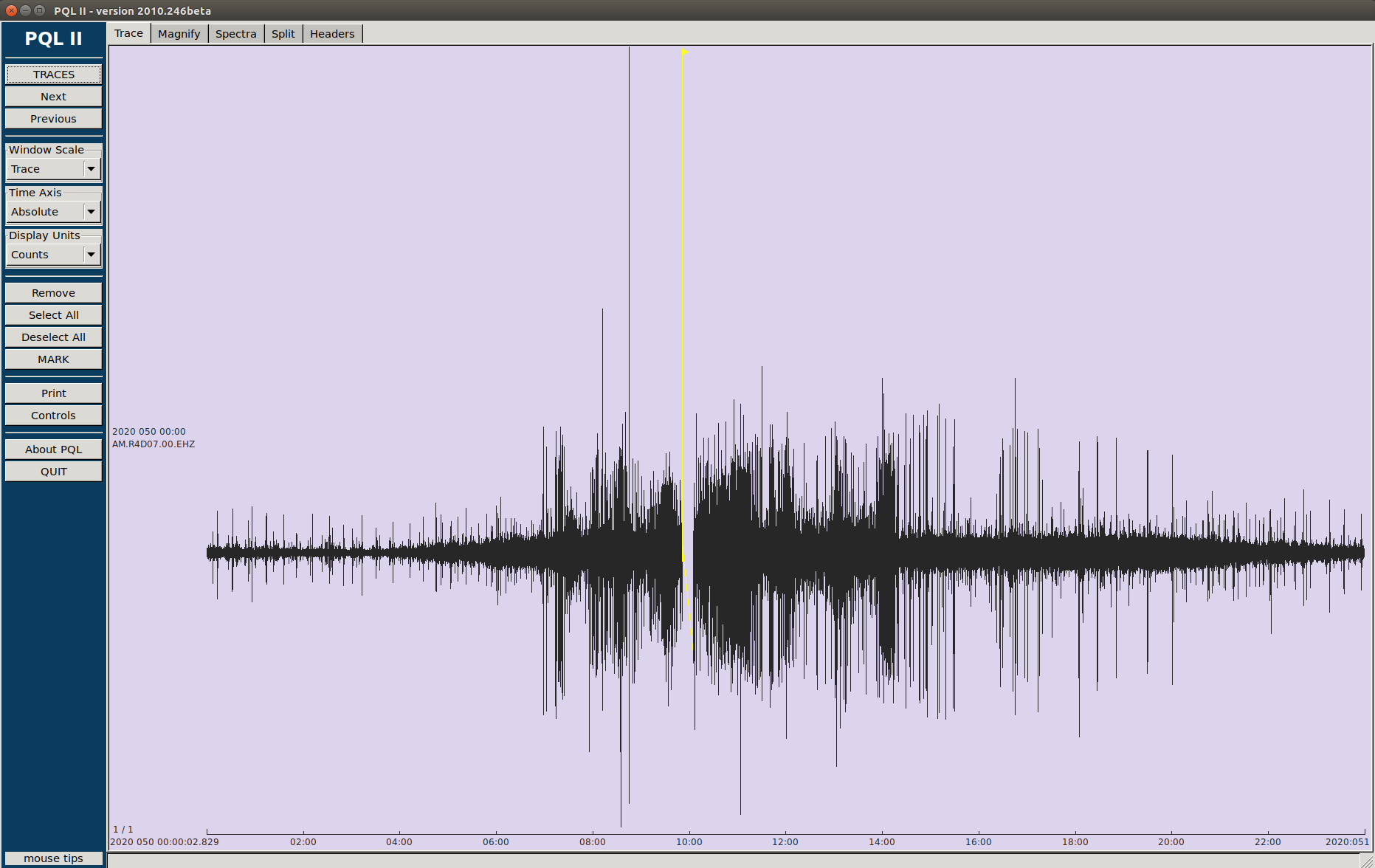
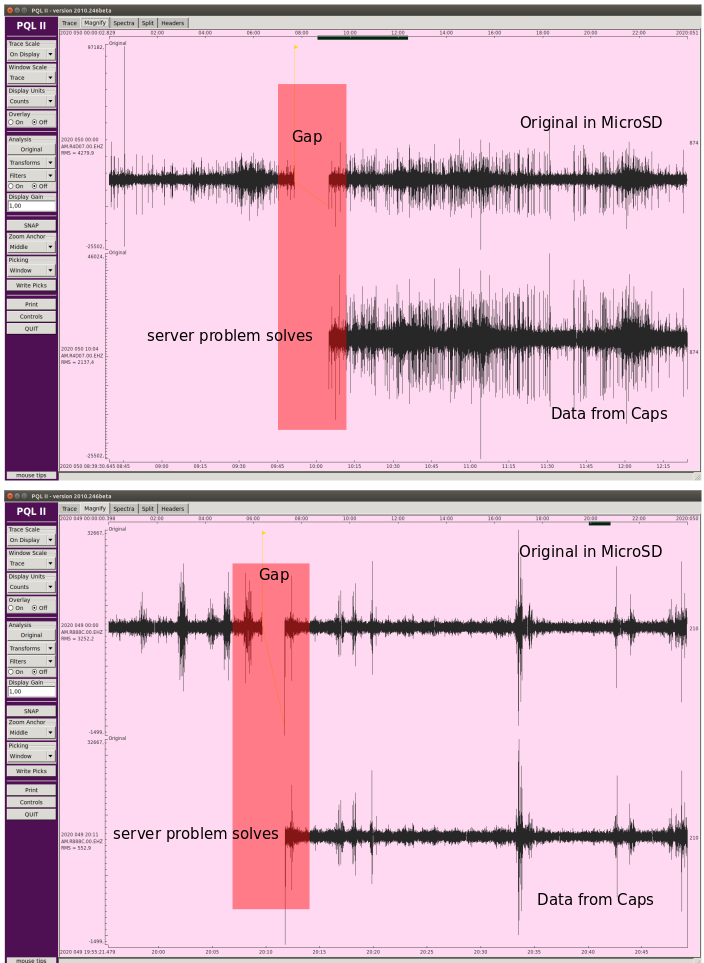
So, if I understood well, you had to act on the server, and it is clear that at point the communication is re-established, we had a gap in both stations. If the problem was the serial port, why do we have data, before and after this server un-banning, in the microSD ¿?
- “as well, i would agree that this is not related to your daily download since you are doing this on several units and see problems with only one. (is that correct?)”
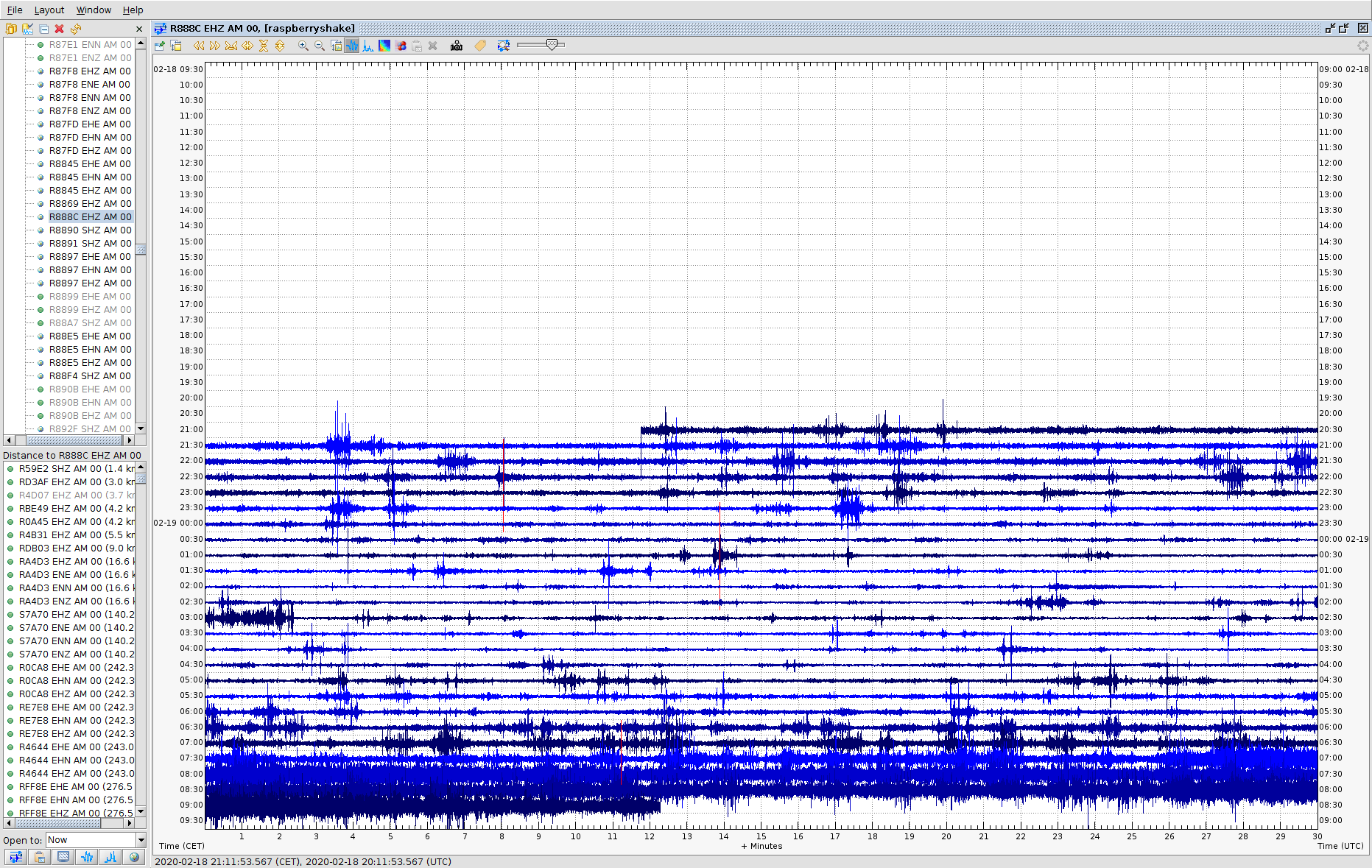
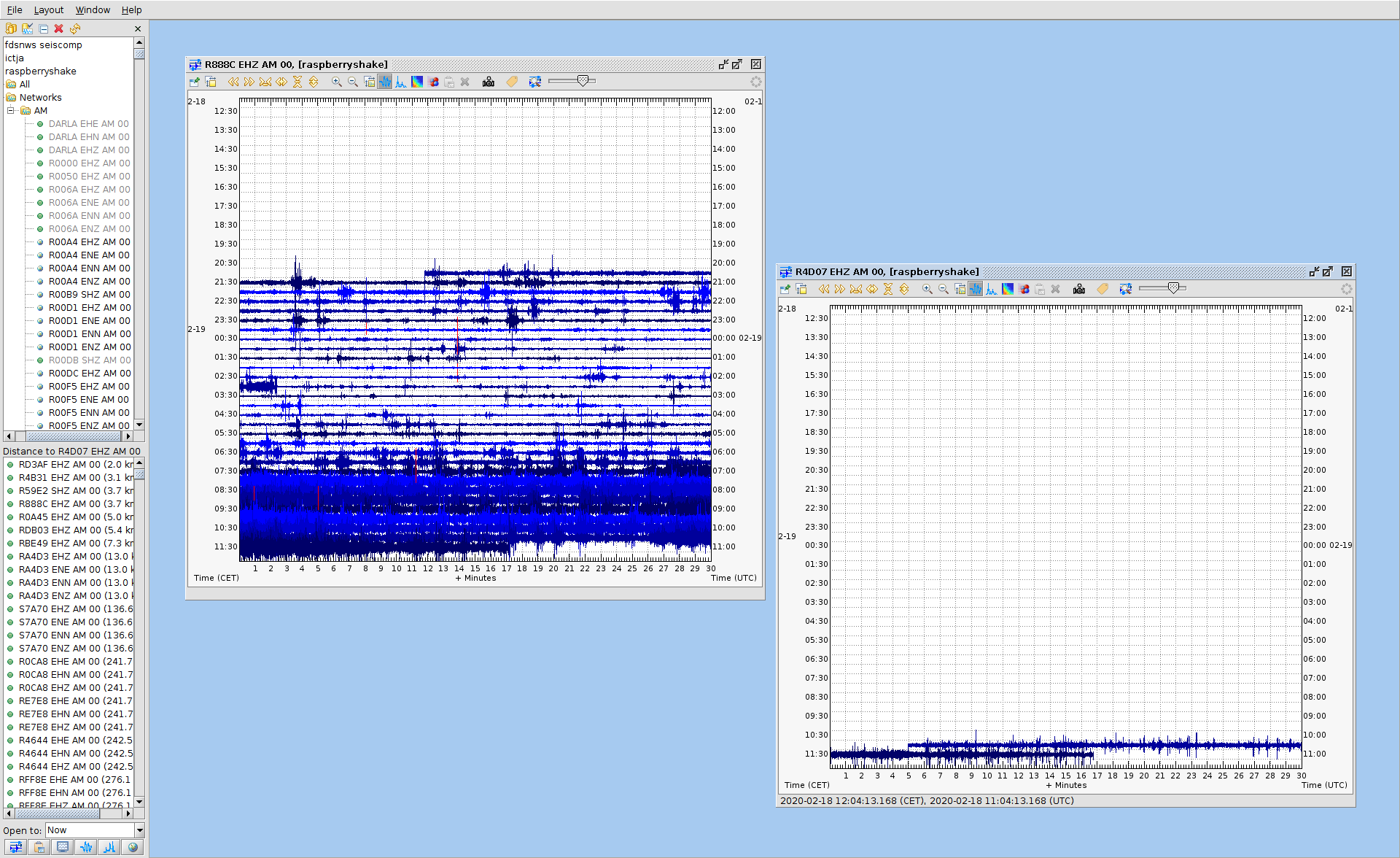
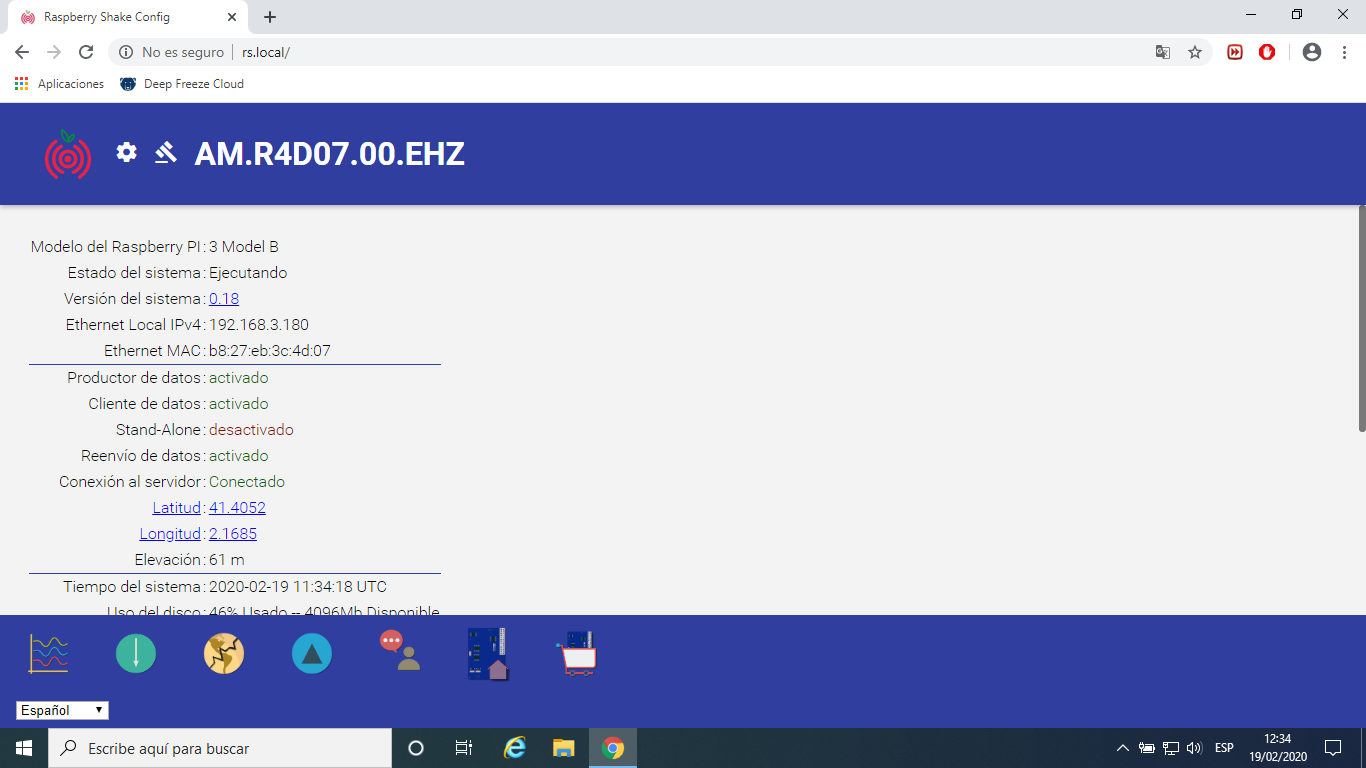
Yes and No. Yes, We are running this script in 9 RS and never found anything strange… Only on these Two stations (R4D07 and R888C) around the same day… So, No, We had problems in two stations.
- “at this point, i can only suggest to reseat the the Shake board, perhaps this could help. if this continues to be a problem after that, then if you have a spare Pi you could swap it out with, that would answer whether or not the problem sits with the computer. when the problem persists across two Pi’s, then that could point to the problem being with the board itself.”
They are in 8 high schools (plus one at home), nine in total. It will be difficult to act on the 8 RS till we recover the instruments. Now they are working fine, so… The one at home is a RS4D and had a “similar communication/hardware problems”, but I changed the PI, re-burned the microSD 3 times and plugged it to the ethernet connector of a wifi tplink repeater, and it works better now (RS 4D Continously rebooting). I’m really concerned with the problems at home when working with wifi, I had a lot of gaps and strange resets, but now it is difficult to know, as I changed all the configuration. So we can leave this one apart …
- “let me know any more of what you find. speaking of which, it would be nice if you could put numbers on this: how often does it happen, and how long is each outage?”
The only way to know and quantify this is running a msi over the mseed copied from the microSDs cards, please find the resulting file attached. I only run it over 2020 data, it is long… The problem is that we won’t have the logs, I can have them for 4, maximum 5, RS, so it will be difficult to know their origin, but what it is sure is that they are not transmission gaps to caps server …
Best regards
Mario
rasp_2020_gaps.txt (147.6 KB)
 hahaha
hahaha


 )
)