In order to compare with other infrasound monitors, I would like to know what the default sensitivity of the RBoom is. I suppose this would be expressed as counts per pascal or millibar or something similar. I see a gain number of 4000 in the instrument response file - is that related?
Ken
Ken:
Buenos días.
That is related but we have not yet accurately determined the real sensitivity of the boom channels. I hope to release that in the coming months.
Branden
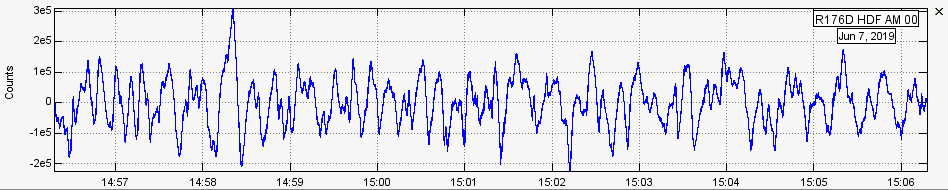
OK. My observation is that with no differential pressure (both ports connected together with a short piece of tubing) I get nice white noise output with a peak-to-peak amplitude of +/- 1000 counts. This seems a bit much, considering that the A/D conversion creates +/- 7 counts (per previous note on the shake).
Can I change a parameter in a file on the boom to tone things down?
Nope. The self-noise is the self-noise. You cannot change it without choosing a different sensor.
branden
OK, so some of the noise is coming from the sensor as well as the A/D. But still, I would like to just “turn down the volume” so that I don’t see all kinds of exponential numbers, even during a quiet period. I think that the data compression algorithm might be a lot happier as well and this might make the display in SWARM work a bit faster … I am thinking I would like to see SWARM display something like +/- 10 counts in the absolutely-no-real-signal situation. I know the signal will go way way up when I connect the port to the atmosphere.
Yes.
There is no gain setting. The exponential numbers are not in the raw waveform view but in the power spectrum, so that is completely normal.
That is just not possible.
actually I was getting exponent-sized numbers (>100K) in the waveform view. It probably has to do with the random-sized piece of tubing I am using for a “filter” - let me hold off until I get the proper filter on there
I still think the no-signal magnitude is having an impact on the size of the compressed data files (i.e., the compression is not working with this wild and crazy data).
Ken
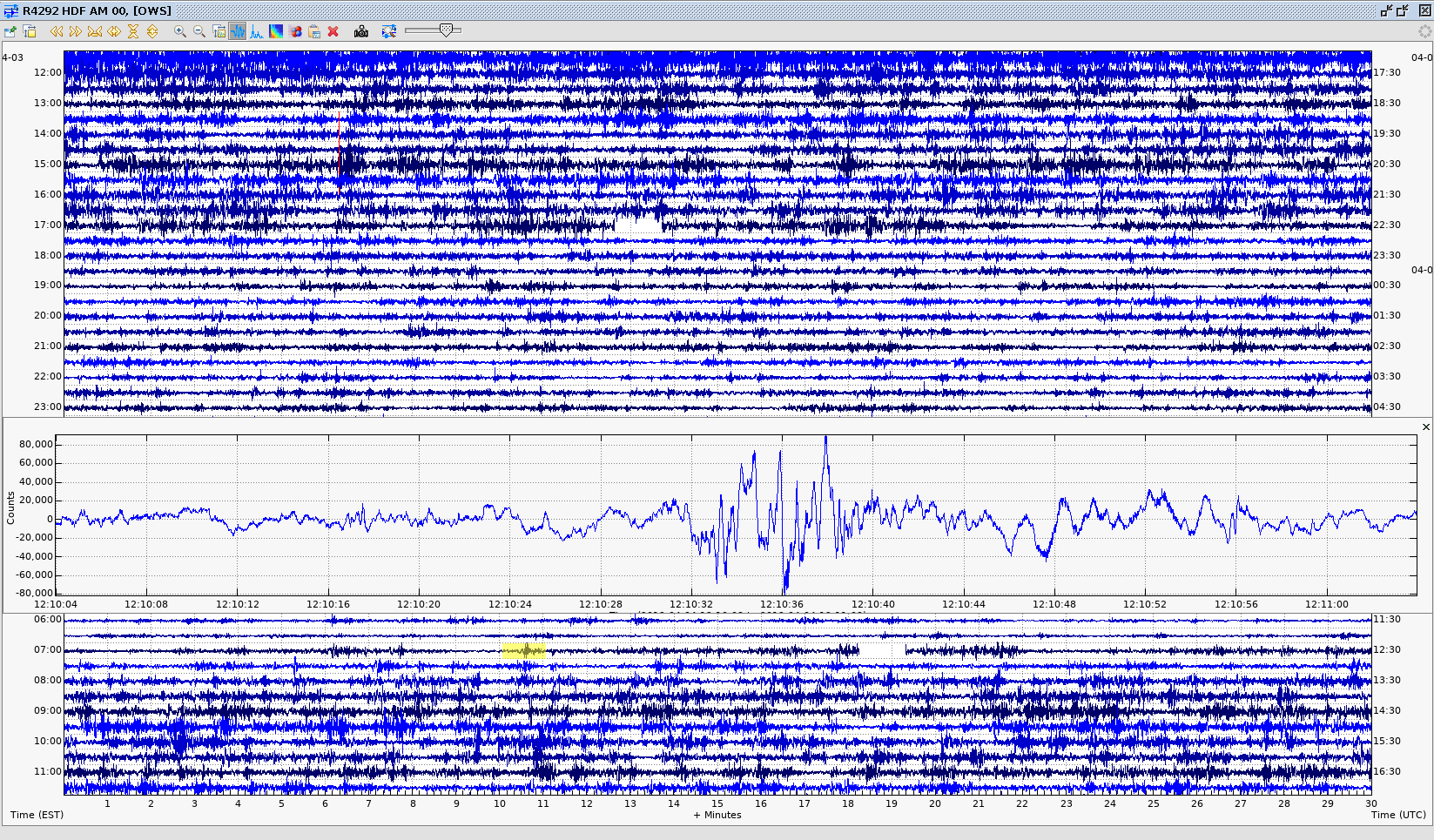
Send me your BOOM’s serial number and I will send you an image of what you data looked like in the lab with the filter in place.
The compression algorithm has no problem with this data. It can handle the full 24-bit range, or up to +/- 8,388,608 counts.
I found it in our records. Here is what things looked like during testing, so this is what you can expect when the mechanical filter arrives!:
(so 10s of 1000s of counts is normal)
branden
I am just talking about the size - after compression - being larger, due to more bits being required to represent the data (of which much is just noise). If the size is not being effectively reduced by the compression algorithm, then the compression is “not working” very well on that data.
Looking in /opt/data/archive/2019/AM/R176D/HDF.D I can see files nearly double the size of my RD1D.
Will send serial number by direct mail.
Ken
Ummm…
Perhaps the files are double the size because the sampling frequency is double? (100 Hz vs 50 Hz)
No - both 100 Hz.
Perhaps there really is more data in the sound file than the seismic file. The earth acts as a big low pass filter, I suppose, and air just does not have much inertia. Still, I suspect if you were to divide all the data points by 100 before feeding it into the compression algo, it would result in a smaller file. Sure you would be throwing away something, but given that the background noise amounts to +/-1000 counts, I don’t think you are losing much.
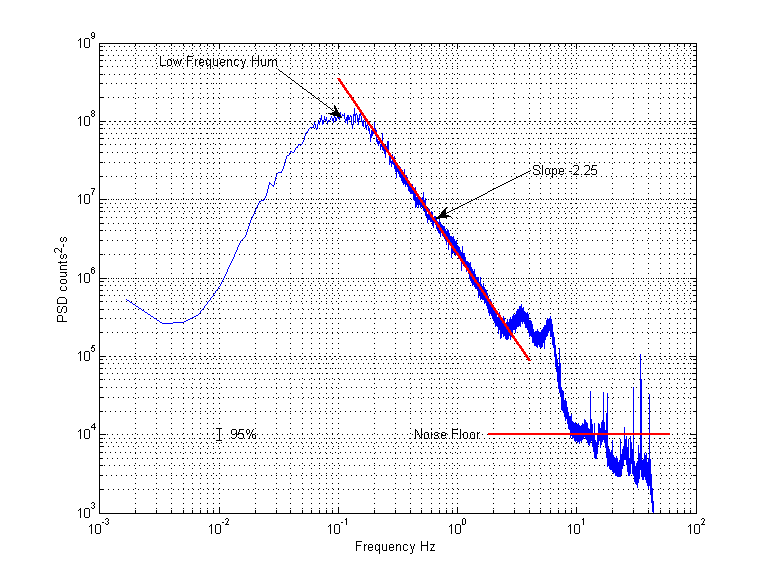
I disagree that these data are “wild and crazy”. In Fourier space, they look quite reasonable:
Where I’ve processed a day of data, ensemble averaging using 10 minute windows. We were not home, so there was no human-generated noise.
The spectrum shows a broad band of low-frequency hum (5 to 20 s periods), which you can plainly see in the time series posted above. The energy decays with a slope of -2.25, which is too much for there to be any persistence (i.e., no fractal properties). My estimate of the noise floor of the instrument is 1e4 below the peak indicating we are getting good precision from the instrument.
I have no idea what the low-frequency hum is. I think it’s too low for the human ear to detect…
My comments are not on the quality of the instrument, but rather on the appropriateness of using the same data compression algorithm as the seismic data on this otherwise unconditioned data stream. MiniSeed uses a lossless compression scheme. It does not lose any data - or noise. I understand that it compresses the time-series data by storing differences between successive values and using fewer bits to store smaller differences. The noisier the data, the less-well it will compress. We know actual data from RBOOM has +/- 1000 counts of noise on it. The algorithm will preserve every bit of that noise, thus wasting as many as 10 bits for each sample. I suggest that this is the main reason the data does not compress as well as the RSHAKE data (which has something like +/- 7 counts of noise on it).
Scaling the RBOOM data to a lower range of values would reduce the number of bits needed to store successive values of the time series. Dividing the values by e.g. 100 before presenting them to the compression algo would mean that there would be only +/-10 counts of noise and it would look a lot like RSHAKE data and probably compress in a similar ratio.
I am not a data scientist, so apologies in advance for any blunders.